What To Know About Postgres if You’re Coming From SQL Server
Peeking over the other side of SQL

1989. The year the Berners-Lee proposed the World Wide Web, The Simpsons first premiered, and Taylor Swift was born. Another worldwide phenom was born that year: Microsoft SQL Server 1.0.
We’ve had 35 years of SQL Server (Microsoft’s version), and if you’ve been invested in the MS ecosystem, SQL Server has probably been your RDBMS of choice. I know this world well—my time at Microsoft put me in touch with their database landscape, from SQL Server to Cosmos DB.
But now that the Microsoft world is opening up more and more to Postgres, you might consider joining the dark side.

This shift makes sense. Postgres was also born in 1989 and has steadily grown into the most-loved database by developers today. As Microsoft embraces open-source solutions and cross-platform compatibility, more MS SQL developers are opening up to the Postgres ecosystem.
So if this is you, what do you need to know about Postgres if you’re most familiar with SQL Server?
Languages vs. dialects
Similarly, Postgres and SQL Server speak the same language—SQL—but with different dialects. SQL Server speaks T-SQL (Transact-SQL), Microsoft’s proprietary extension to SQL that adds procedural programming elements like variables, flow control, and exception handling.
Postgres, on the other hand, uses PL/pgSQL (Procedural Language/PostgreSQL), a procedural language that extends standard SQL by adding control structures, complex calculations, and custom data types.
This means that while both are SQL at heart, they each have their quirks and conventions. We will set up two databases, one on the SQL server and one on Neon with Postgres, and see some of the differences between the two.
About Neon
String delimiters
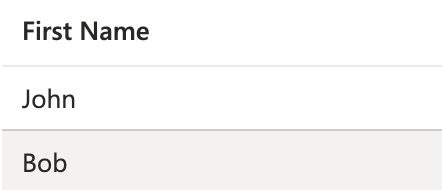
In SQL Server, you’re used to using square brackets [column_name] to handle spaces or reserved words in identifiers.
SELECT [First Name] FROM [Customer Table] WHERE [Status] = 'Active'In our toy db, we get this:
In Neon, this query will bring up this error:

“SQLSTATE 42601” just means syntax error. Postgres uses double quotes “column_name” instead.
SELECT "First Name" FROM "Customer Table" WHERE "Status" = 'Active'To yield:

In both systems, regular column names without spaces or special characters don’t need delimiters, and string values always use single quotes.
Date functions
WHERE you’d use GETDATE() in SQL Server, you’ll use CURRENT_DATE in Postgres. DATEADD becomes + INTERVAL, and DATEDIFF works quite differently between the two.
SELECT
GETDATE() as current_dt,
DATEADD(day, 7, OrderDate) as week_later,
DATEDIFF(day, OrderDate, ShipDate) as days_to_ship
FROM Orders;This in SQL Server gives you:

In Neon, though, it will give you:
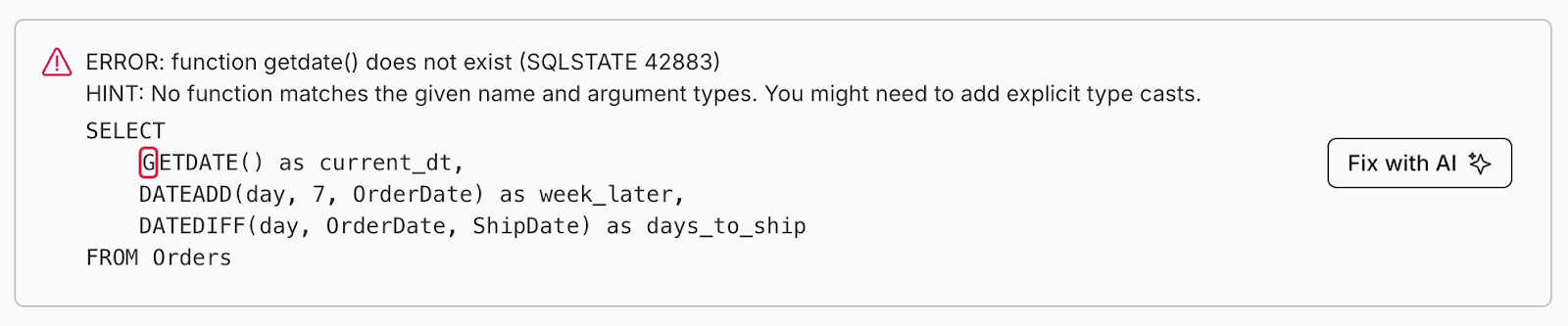
A nice note if you are used to Azure–Neon gives you good guidance via the error messages (and the “Fix with AI” if needed).
You want this in Postgres:
SELECT CURRENT_TIMESTAMP as current_dt,
OrderDate + INTERVAL '7 days' as week_later,
(ShipDate - OrderDate) as days_to_ship
FROM Orders;To give you the answer:

Postgres also offers more granular extraction with its EXTRACT function:
SELECT EXTRACT(EPOCH FROM timestamp) FROM table;TOP vs LIMIT
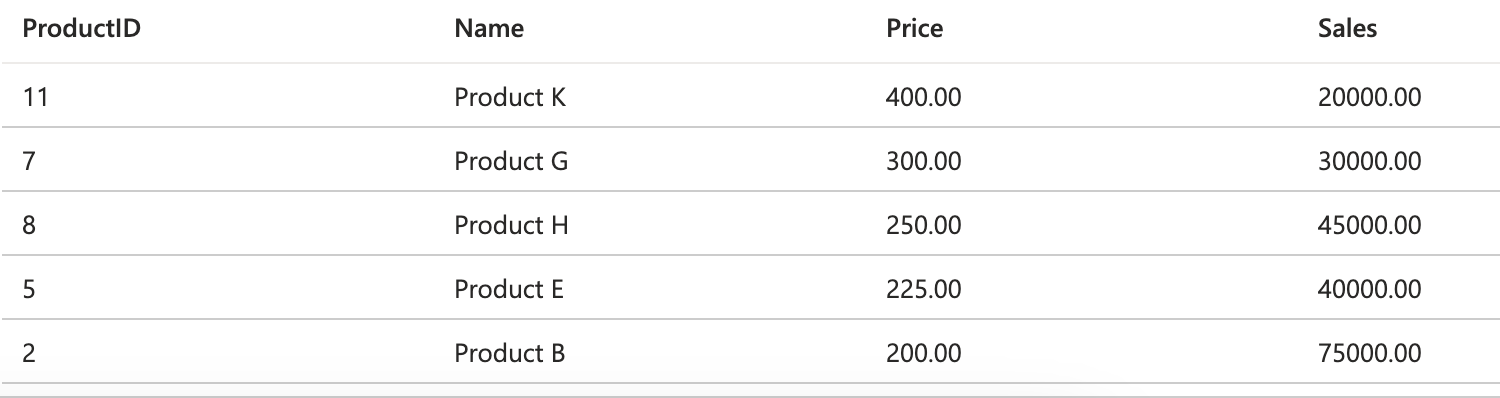
This is one of the changes you might miss from SQL Server. T-SQL has TOP, with optional ties and percent:
SELECT TOP 10 WITH TIES *
FROM Products
ORDER BY Price DESC;
SELECT TOP 5 PERCENT *
FROM Products
ORDER BY Sales;Giving you these:

Postgres doesn’t have these helpers. Instead, you have to use LIMIT, often with OFFSET for pagination:
SELECT *
FROM Products
ORDER BY Price DESC
LIMIT 10
-- With pagination
SELECT * FROM Products
ORDER BY Sales
LIMIT 5 OFFSET 10 -- Skip first 10, take next 5
Identity vs serial
IDENTITY is how you’ll be creating auto-incrementing columns in SQL Server.
CREATE TABLE Products (
ProductID INT IDENTITY(1,1) PRIMARY KEY,
Name VARCHAR(100)
);In Postgres, the same outcome can be produced using SERIAL:
-- Traditional SERIAL
CREATE TABLE Products (
ProductID SERIAL PRIMARY KEY,
Name VARCHAR(100)
);However, after Postgres 10, IDENTITY was introduced, so you can continue using that if necessary (though SERIAL is idiomatic in Postgres):
-- New IDENTITY (PostgreSQL 10+)
CREATE TABLE Products (
ProductID INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
Name VARCHAR(100)
)Concatenation
SQL Server uses the + operator for string concatenation, like in C++ and Python:
SELECT [First Name] + ' ' + [Last Name] as [Full Name],
SUBSTRING(Description, 1, 100) + '...' as Short_Desc
FROM [Customer Table]
WHERE LEN(Description) > 100;Outputting:

Postgres uses the SQL standard || for concatenation:
SELECT "First Name" || ' ' || "Last Name" as "Full Name",
SUBSTR(Description, 1, 100) || '...' as Short_Desc
FROM "Customer Table"
WHERE LENGTH(Description) > 100;Output:

These might seem like small differences, but they can trip you up without expecting them. The good news is that both dialects are well-documented, and most modern IDEs can help you navigate these differences. Plus, many fundamental concepts–JOINs, WHERE clauses, GROUP BY–work exactly the same way.
Let’s look at more complex queries to show the similarities/differences. First, some string searching with different approaches. The SQL Server version:
SELECT
[First Name] + ' ' + [Last Name] as [Full Name],
email,
CASE
WHEN email LIKE '%@%.com' THEN 'Commercial'
WHEN email LIKE '%@%.org' THEN 'Organization'
ELSE 'Other'
END as EmailType,
LEN(Description) as DescriptionLength
FROM [Customer Table]
WHERE
Description LIKE '%long%'
AND [Status] = 'Active';Eliciting this response:

Then, the Postgres version:
SELECT
"First Name" || ' ' || "Last Name" as "Full Name",
email,
CASE
WHEN email ~ '@[^@]+\.com$' THEN 'Commercial'
WHEN email ~ '@[^@]+\.org$' THEN 'Organization'
ELSE 'Other'
END as EmailType,
LENGTH(Description) as DescriptionLength
FROM "Customer Table"
WHERE
Description ~ 'long'
AND "Status" = 'Active';This gets us this:

We see similar structure and intent in both queries but different syntax approaches. SQL Server uses the simpler LIKE operator with wildcards for pattern matching, while Postgres leverages more powerful POSIX regular expressions with the ~ operator.
Postgres’ regex approach is more precise and flexible – note how it uses ‘@[^@]+.com$’ to ensure the .com appears at the end of the string, while SQL Server’s ‘%@%.com’ is less strict. Both databases handle string concatenation and CASE statements similarly, though with different operators (+ vs ||).
Importantly when playing with strings, while SQL server is case-insensitive by default, Postgres is case-sensitive.
Another example with grouping. The SQL Server way:
WITH CustomerStats AS (
SELECT
c.CustomerID,
[First Name] + ' ' + [Last Name] as FullName,
COUNT(o.OrderID) as OrderCount,
AVG(DATEDIFF(day, OrderDate, ShipDate)) as AvgProcessingTime
FROM [Customer Table] c
LEFT JOIN Orders o ON c.CustomerID = o.OrderID
GROUP BY c.CustomerID, [First Name], [Last Name]
)
SELECT TOP 5 WITH TIES
cs.FullName,
cs.OrderCount,
cs.AvgProcessingTime,
p.Name as MostExpensiveProduct,
p.Price
FROM CustomerStats cs
CROSS APPLY (
SELECT TOP 1 Name, Price
FROM Products
ORDER BY Price DESC
) p
ORDER BY cs.OrderCount DESC;Output:

The Postgres way:
WITH CustomerStats AS (
SELECT
c.CustomerID,
"First Name" || ' ' || "Last Name" as FullName,
COUNT(o.OrderID) as OrderCount,
AVG(EXTRACT(EPOCH FROM (ShipDate - OrderDate))/86400) as AvgProcessingTime
FROM "Customer Table" c
LEFT JOIN Orders o ON c.CustomerID = o.OrderID
GROUP BY c.CustomerID, "First Name", "Last Name"
)
SELECT
cs.FullName,
cs.OrderCount,
cs.AvgProcessingTime,
p.Name as MostExpensiveProduct,
p.Price
FROM CustomerStats cs
CROSS JOIN LATERAL (
SELECT Name, Price
FROM Products
ORDER BY Price DESC
LIMIT 1
) p
ORDER BY cs.OrderCount DESC
LIMIT 5;Output:

While both use CTEs, their approach to lateral joins differs–SQL Server uses CROSS APPLY while Postgres uses CROSS JOIN LATERAL. The date calculations also diverge significantly, as we showed above. However, the main takeaway from these examples is that they are mostly the same. The language is always SQL; It’s just the “accent” that’s different.
Postgres is the community
Moving away from the specifics of syntactic play in SQL Server and Postgres, it is also essential to understand fundamentally that Postgres and SQL Server are “built” differently. By this, we mean that Postgres is open-source and thus built by the community, whereas SQL Server is a Microsoft product and thus built by a company.
This manifests in different ways. First, in how features are developed and rolled out. In SQL Server, features come through Microsoft’s product roadmap–they’re carefully planned, extensively tested, and released in major versions with precise deprecation schedules. When Microsoft decides to add temporal tables or JSON support, it happens comprehensively and with extensive documentation.
Postgres, by contrast, evolves through community consensus and contribution. For instance, here are Neon developers’ contributions to Postgres 17. Features might start as extensions before being incorporated into core, and different distributions might support different feature sets. For instance, the popular uuid-ossp module for UUID generation isn’t part of the core installation–you’ll need to explicitly enable it with CREATE EXTENSION. This modularity is both a strength and a complexity you’ll need to navigate.
This community-driven nature extends to tooling as well. Where SQL Server Management Studio (SSMS) is the de facto standard for SQL Server development, Postgres users choose between pgAdmin, DBeaver, DataGrip, and dozens of other tools (such as Neon). Each has its strengths and user communities. The same goes for monitoring, backup solutions, and other operational tools–you’re not locked into a single vendor’s ecosystem.
Even the way you think about database hosting changes. SQL Server’s licensing model pushes you toward specific deployment patterns–you carefully plan your core counts and instance placements to optimize licensing costs. With Postgres, you can experiment with different hosting models, from self-hosted to managed services like Neon or Amazon RDS, each with its own community-developed best practices and optimization techniques.
It’s a different mindset–less about mastering a single vendor’s product and more about participating in a global community of database professionals. For example, let’s say you need to implement full-text search. In SQL Server, you’d typically use the built-in full-text search capabilities:
SELECT Title, Description
FROM Products
WHERE CONTAINS(Description, 'FORMSOF(INFLECTIONAL, "running")');In Postgres, you might choose between built-in text search:
SELECT title, description
FROM products
WHERE to_tsvector('english', description) @@ to_tsquery('english', 'running:*');You might also opt for Elasticsearch or use the pg_trgm extension for trigram-based similarity search. Each approach has a community of users, contributors, and best practices.
This community-driven development also means that Postgres often gets cutting-edge features before they appear in commercial databases. For instance, the JSONB data type and operations in Postgres predated SQL Server’s JSON support by several years. The tradeoff is that you must be more proactive about staying current with community developments and best practices.
Switching worlds
There are a ton of good reasons to stay with SQL Server. The Microsoft ecosystem is deeply integrated and well-supported, and if your team has years of T-SQL expertise, that’s valuable institutional knowledge. Plus, Microsoft’s development pace has picked up significantly in recent years, with features like ledger tables and intelligent query processing showing they’re still innovating (and, of course, their integration of Neon in Azure).
However, there are also great reasons to move to Postgres. The rapid pace of community innovation means you’re often getting cutting-edge features years before they appear in commercial databases, and the freedom to choose your tools, hosting, and extensions gives you unprecedented flexibility in building your stack. The vibrant community means you’re never solving problems alone.
Ultimately, that choice is yours. But if you’re curious, check out Neon—it’s the fastest way to get a Postgres database up and running.
You can also deploy Free Neon databases directly via the Azure portal.