Migrating Schemas Across Many Neon Projects Using DrizzleORM
A practical guide to managing multiple databases per tenant with the same schema using DrizzleORM and Neon

In this blog post, we’ll explain how you can use a combination of DrizzleORM, GitHub Actions, the Neon API, and a couple of custom template scripts to manage multiple databases using the same database schema.
You can find all the code referenced in this blog post on this repo:
https://github.com/neondatabase-labs/neon-database-per-tenant-drizzle
But first,
What is Database Per Tenant?
A database-per-tenant model is an architectural approach in which each tenant (user, client, or project) has its own dedicated database instance.
While the databases are separate, they often share the same schema. For example, a project management tool like Asana or Trello might implement this model, where each company or team using the software has its own dedicated database to store project data, tasks, user information, permissions, and more. However, the structure and method of data storage remain consistent across all companies or teams.
Developing and maintaining this type of software requires new customers and their databases to be created using the same schema. Additionally, any changes to the database schema must be rolled out to all individual databases simultaneously, which can be quite challenging to manage.
Thankfully, we now have tools that make this process much easier.
A Method For Schema Migrations
Example requirements
To demonstrate the method, we’ll set up an example architecture with 4 Neon databases (customers), each one living on its own Neon project, all using Postgres 16 and all deployed to AWS us-east-1 (although, Neon can also deploy to Azure).
The schema consists of three tables: users, projects and tasks. You can see the schema here: schema.ts, and for good measure, here’s the raw SQL equivalent: schema.sql.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT,
owner_id INT REFERENCES users(id) ON DELETE CASCADE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT,
assignee_id INT REFERENCES users(id),
due_date TIMESTAMP,
status VARCHAR(20) DEFAULT 'in_progress',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);This default schema is referenced by each of the drizzle.config.ts files that have been created for each of our customers. For each of the customers, quite a few files and variables are required, and setting these all up manually is a recipe for disaster—the solution: to automate everything.
The complete workflow, explained
tip
Now, we’ll walk you through the workflow. We’ll be using three scripts:
- The create script (
create.js) automates creating new Neon projects via the Neon API. - The generate script (
generate.js) lists all projects in the Neon account, and for each project,- Creates a DrizzleORM configuration file if it doesn’t exist
- Generates migration files using Drizzle Kit
- Creates a GitHub secret for the database connection string
- Updates the GitHub Action workflow to include the new secret
- Finally, the migrate script (
migrate.js) is automatically triggered by the GitHub Action, running shema migrations for all projects by reading their DrizzleORM config files.
The create script
To create new Neon projects in this example, we’ve created a simple CLI using commander and use the Neon API createProject method:
import { Command } from 'commander';
import { createApiClient } from '@neondatabase/api-client';
import 'dotenv/config';
const program = new Command();
const neonApi = createApiClient({
apiKey: process.env.NEON_API_KEY,
});
program.option('-n, --name <name>', 'name of the company').parse(process.argv);
const options = program.opts();
if (options.name) {
console.log(`Company Name: ${options.name}`);
const response = await neonApi.createProject({
project: {
name: options.name,
pg_version: 16,
region_id: 'aws-us-east-1',
},
});
const { data } = await response;
console.log(data);
} else {
console.log('No company name provided');
}The src for this script can be found here: src/scripts/create.js.
To use this CLI, you can run the following command in your terminal:
npm run create -- --name="ACME Corp"This will set up a new Neon project named “ACME Corp” with a PostgreSQL 16 database, deployed to AWS in the us-east-1 region.
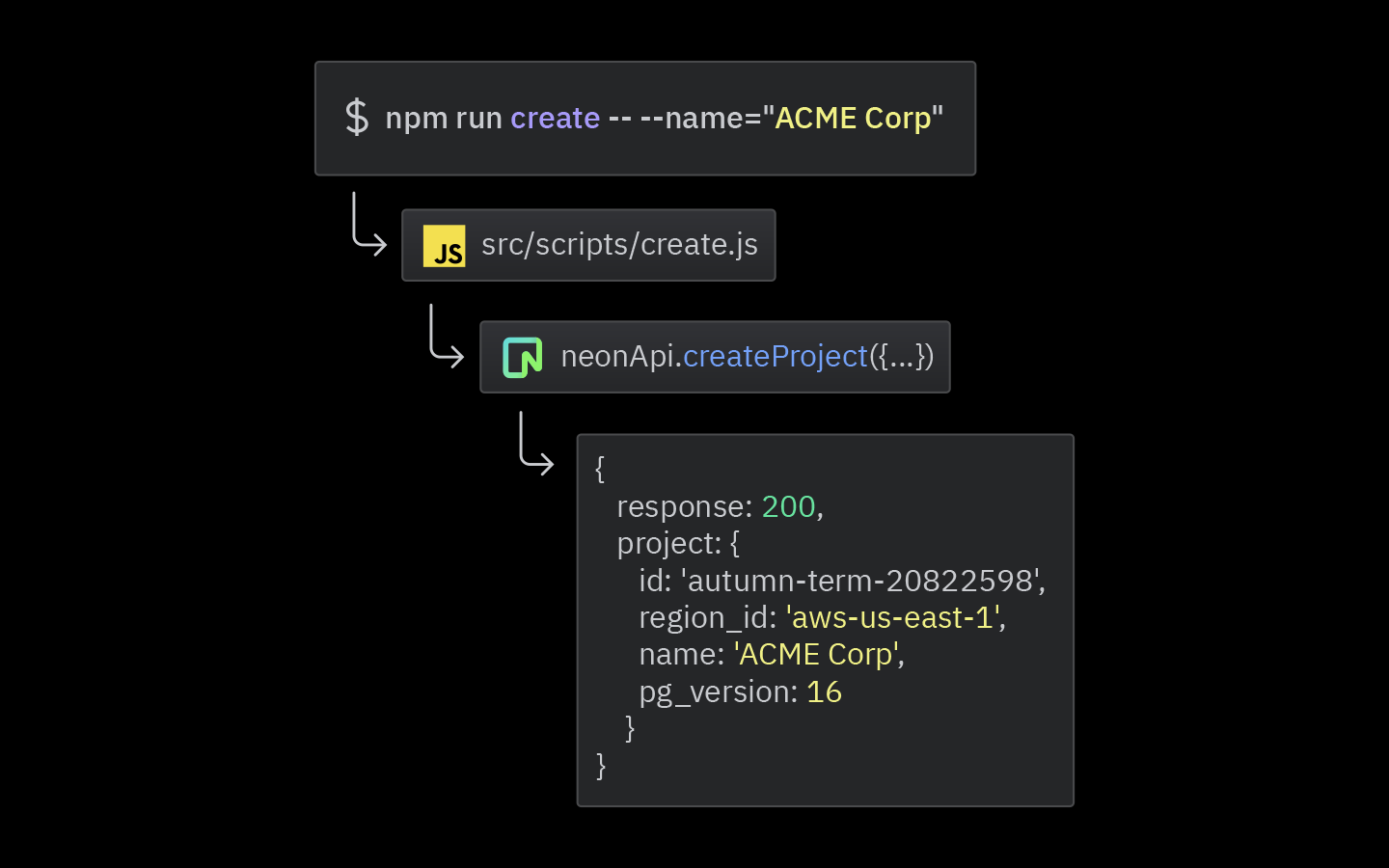
In our example, we’ve used this same approach to create 4 projects. They are:
- ACME Corp
- Payroll Inc
- Finance Co
- Talent Biz
To use this Neon API you’ll need to create an API key. You can read more about API keys in the docs: Create an API key.
The generate script
There’s quite a lot going on in this script, but in short, the generate script does the following.
- Lists all projects using the Neon API
- For each project found, it will create the necessary DrizzleORM config files (if they don’t exist)
- Run drizzle-kit generate
- Create a GitHub secret (environment variable) within the repository
- Update the GitHub Action workflow .yml file, adding in a reference to the secret (environment variable).
After the code snippet, we’ll break down each step in more detail.
import { existsSync, mkdirSync, writeFileSync } from 'fs';
import { execSync } from 'child_process';
import { createApiClient } from '@neondatabase/api-client';
import { Octokit } from 'octokit';
import 'dotenv/config';
import { encryptSecret } from '../utils/encrypt-secret.js';
import { drizzleConfig } from '../templates/drizzle-config.js';
import { githubWorkflow } from '../templates/github-workflow.js';
const octokit = new Octokit({ auth: process.env.PERSONAL_ACCESS_TOKEN });
const neonApi = createApiClient({
apiKey: process.env.NEON_API_KEY,
});
const repoOwner = 'neondatabase-labs';
const repoName = 'neon-database-per-tenant-drizzle';
let secrets = [];
(async () => {
if (!existsSync('configs')) {
mkdirSync('configs');
}
const { data: publicKeyData } = await octokit.request(
`GET /repos/${repoOwner}/${repoName}/actions/secrets/public-key`,
{
headers: {
'X-GitHub-Api-Version': '2022-11-28',
},
}
);
const response = await neonApi.listProjects();
const {
data: { projects },
} = await response;
await Promise.all(
projects.map(async (project) => {
const { id, name } = project;
const response = await neonApi.getConnectionUri({
projectId: id,
database_name: 'neondb',
role_name: 'neondb_owner',
});
const {
data: { uri },
} = await response;
const safeName = name.replace(/\s+/g, '-').toLowerCase();
const path = `configs/${safeName}`;
const file = 'drizzle.config.ts';
const envVarName = `${safeName.replace(/-/g, '_').toUpperCase()}_DATABASE_URL`;
const encryptedValue = await encryptSecret(publicKeyData.key, uri);
secrets.push(envVarName);
if (!existsSync(path)) {
mkdirSync(path);
console.log('Set secret for :', safeName);
}
if (!existsSync(`${path}/${file}`)) {
writeFileSync(`${path}/${file}`, drizzleConfig(safeName, envVarName));
console.log('Create drizzle.config for:', safeName);
}
if (!existsSync(path) || !existsSync(`${path}/${file}`)) {
await octokit.request(`PUT /repos/${repoOwner}/${repoName}/actions/secrets/${envVarName}`, {
owner: repoOwner,
repo: repoName,
secret_name: envVarName,
encrypted_value: encryptedValue,
key_id: publicKeyData.key_id,
headers: {
'X-GitHub-Api-Version': '2022-11-28',
},
});
}
execSync(`drizzle-kit generate --config=${path}/${file}`, { encoding: 'utf-8' });
console.log('Run drizzle-kit generate for :', safeName);
})
);
if (!existsSync('.github')) {
mkdirSync('.github');
}
if (!existsSync('.github/workflows')) {
mkdirSync('.github/workflows');
}
const workflow = githubWorkflow(secrets);
writeFileSync(`.github/workflows/run-migrations.yml`, workflow);
console.log('Finished');
})();To use this script, you can run the following from your terminal:
npm run generateThe src for this script can be found here: src/scripts/generate.js.
You can create a GitHub personal Access Token by following the docs. We opted to use Fine-grained personal access tokens. We limited access to just this repository, set the expiration to no expiration and granted Read and Write access for Secrets.
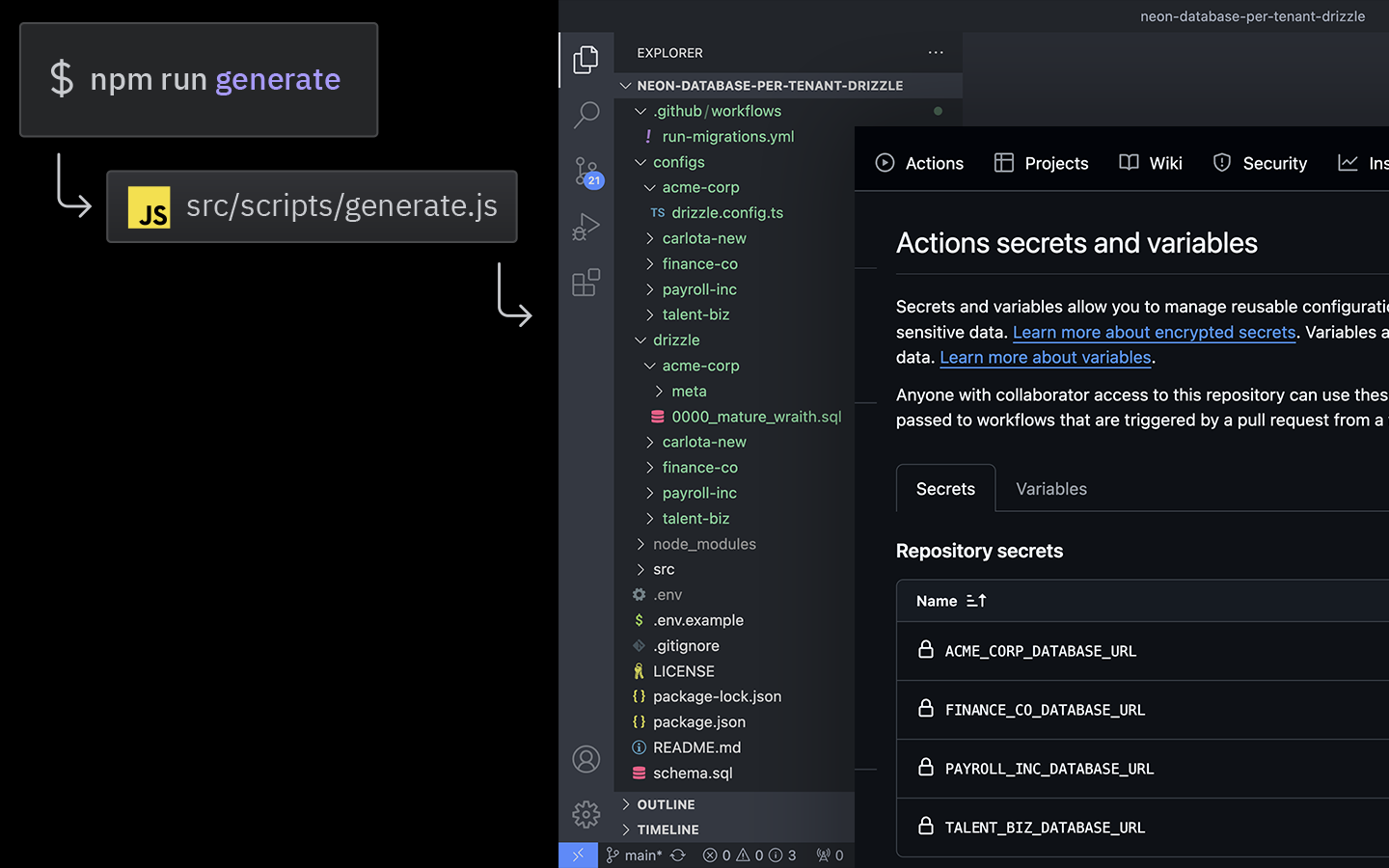
Ok, now, the script. This is what it does:
- There are two variables,
repoOwnerandrepoNamethat define the owner and the name of the repository. Update these to suit your needs. - Check to see if a
configsdirectory exists. If it doesn’t, create one. This will be where a new directory for each project/customer will be created. - Make a request to the GitHub API to get a
publicKeyData. This will be used later by the encryptedSecret utility function. - Make a request using the Neon API to listProjects, which returns a list of projects / customer databases.
- Iterate over each project and use the project id to make a second call to the Neon API, getConnectionUri, to get the connection string for each.
- Create new variables for:
safeNameuses regex to ensure the customer name is suitable to use a directory name, removing any spaces and converting them to a – and lastly, all characters to lowercase.-
pathvariable is the path to where the DrizzleORM config should be written and uses a hardcoded value of configs, plus thesafeNamevariable. filevariable is the name of the DrizzleORM config file to create.envVarNameis thesafeNamebut converted to uppercase using sme regex to convert the – to an _, plus a hardcoded string of_DATABASE_URL.encryptedValueis the of the encryptedSecret utility function which accepts thepublicKeyDataandurias returned by Neon API encrypted.
- Push each new
envVarNameto the secrets array for reference in a later step. - Check if a directory exists using the path variable, if it doesn’t, create one
- Check if a file exists using both the
pathandfilevariable. - Create the DrizzleORM config file using the
drizzleConfigtemplate which accepts parameters for thesafeNameandenvVarName. Thesrcfor this file can be found here: src/templates/drizzle-config.js.
The result of step 10 file would be similar to the below. You can see the out param from defineConfig correctly uses the safeName, and the dbCredentials.url correctly uses the envVarName.
import 'dotenv/config';
import { defineConfig } from 'drizzle-kit';
export default defineConfig({
out: './drizzle/acme-corp',
schema: './src/db/schema.ts',
dialect: 'postgresql',
dbCredentials: {
url: process.env.ACME_CORP_DATABASE_URL!,
},
});Continuing with the script:
11. Run drizzle-kit generate --config="", which will create a migrations directory and files inside a drizzle directory using the safeName and default schema. You can see the src for the default scheme here: src/db/schema.ts.
12. Make a request to the GitHub API to add the secrets (environment variables) to the repositories secrets
13. Check if .github directory exists
14. Check if workflows directory exists
15. Amend the GitHub Action workflow file using the githubWorkflow template injecting all secrets from the secrets array. The src for this file can be found here: src/templates/github-workflow.js.
The result of step 15 would be similar to the below. You can see in the env section of the Action that a new variable has been added for each project. This is required because the GitHub Action needs explicit access to repository secrets which hold the connection strings, which in turn are needed by DrizzleORM to apply schema changes.
// .github/workflows/run-migrations.yml
name: Migrate changes
on:
pull_request:
types: [closed]
branches:
- main
workflow_dispatch:
env:
TALENT_BIZ_DATABASE_URL: ${{ secrets.TALENT_BIZ_DATABASE_URL }}
PAYROLL_INC_DATABASE_URL: ${{ secrets.PAYROLL_INC_DATABASE_URL }}
ACME_CORP_DATABASE_URL: ${{ secrets.ACME_CORP_DATABASE_URL }}
FINANCE_CO_DATABASE_URL: ${{ secrets.FINANCE_CO_DATABASE_URL }}
jobs:
migrate:
runs-on: ubuntu-latest
if: github.event.pull_request.merged == true
steps:
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
- name: Install dependencies
run: npm ci
- name: Run migration script
run: node src/scripts/migrate.jsThe remaining parts of this action are to check that a PR has been merged before running the following steps:
- Checkout the repository
- Install the required dependencies
- Run drizzle-kit migrate
The src for this script can be found here: src/.github/workflows/run-migrations.yml.
The migrate script
This script only runs when a PR has been merged and will read over the configs directory and apply the migrations as defined by the drizzle.config.ts file for reach projects/customer ensuring all databases are using the same schema.
import { readdirSync, existsSync } from 'fs';
import path from 'path';
import { execSync } from 'child_process';
import { fileURLToPath } from 'url';
(async () => {
const configDir = path.resolve(path.dirname(fileURLToPath(import.meta.url)), '../../configs');
if (existsSync(configDir)) {
const customers = readdirSync(configDir);
const configPaths = customers
.map((customer) => path.join(configDir, customer, 'drizzle.config.ts'))
.filter((filePath) => existsSync(filePath));
console.log('Found drizzle.config.ts files:', configPaths);
configPaths.forEach((configPath) => {
console.log(`Running drizzle-kit for: ${configPath}`);
execSync(`npx drizzle-kit migrate --config=${configPath}`, { encoding: 'utf-8' });
});
} else {
console.log('The configs directory does not exist.');
}
})();We’ve used npx here to run the drizzle-kit migrate command against each drizzle.config.ts file which will ensure all databases have the same schema applied.
The src for the migration script can be found here: src/scripts/migrate.js
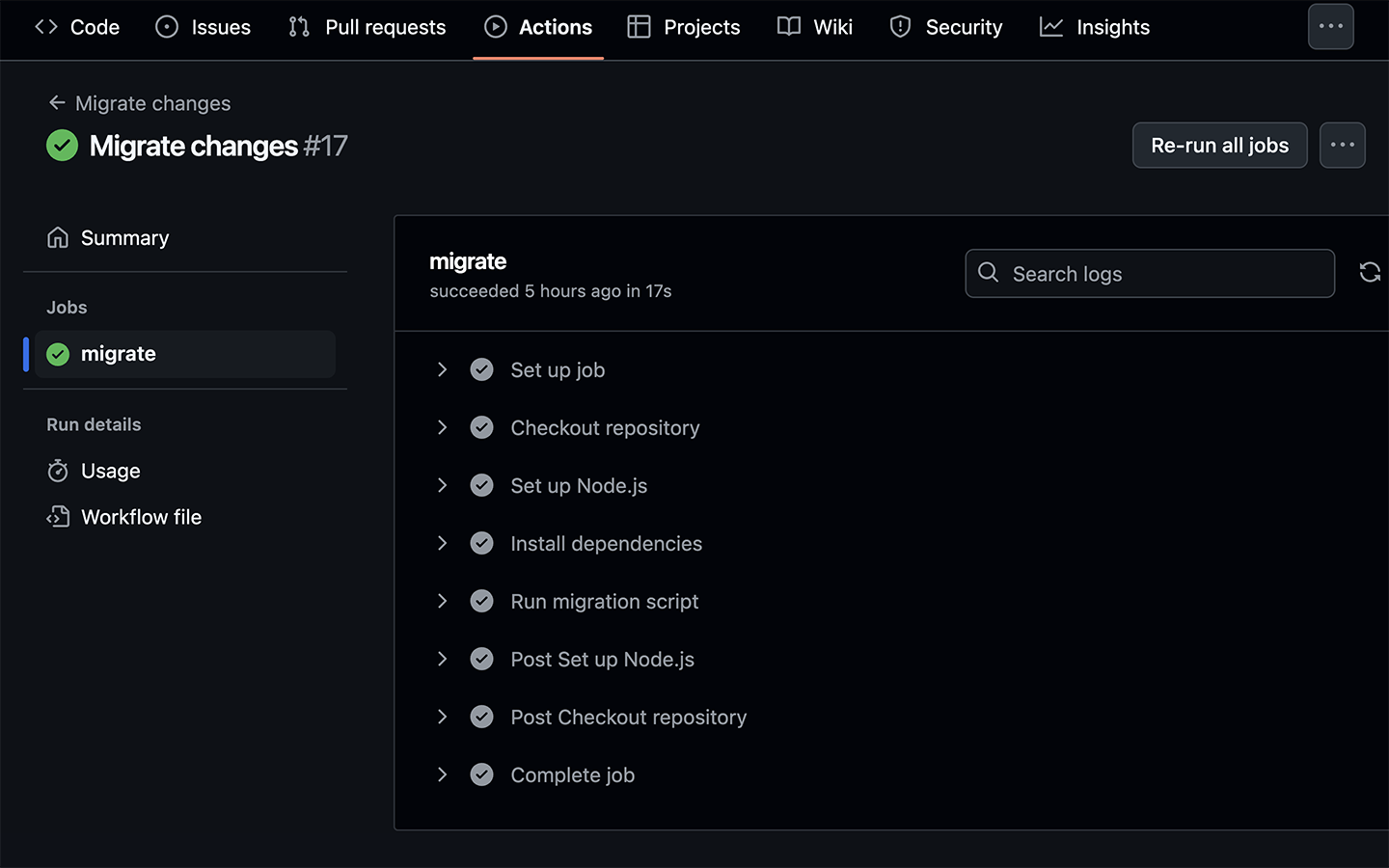
☝️ You won’t be able to run this script locally because the connection strings won’t be set in you local .env file.
This approach will work for any new projects/customers that are added, or when changes to schema are made.
Finished
The most challenging part of the workflow was owing to the individual drizzle.config files that are required for each project/customer. This is no issue if you only have one database, since you’d only have one config file—but if you’re running database-per-tenant, this GitHub Actions workflow is one way to manage your schema migrations.
This is just an example of how you could handle it though. With a bit of creative thinking, and using the GitHub API, it is possible to “dynamically” inject all of the environment variables required to run the migrations using drizzle-kit into the repository secrets and create references in the workflow file.
In an alternative universe, I can see a similar solution being a complete SaaS… But in this universe, you can engineer your own solution using the tools you already have. 🙂
If you have any further thoughts on this workflow, and want to have a chat about it, come find me on X: @PaulieScanlon
Neon is a serverless Postgres platform that helps you ship faster via instant provisioning, autoscaling, and database branching. Its serverless nature makes it ideal for database-per-tenant architectures. We have a generous Free Plan – sign up here.



